Databricks Says AI Agents Need Memory at Scale. They're Solving the Wrong Half of the Problem.
The largest data platform in the world just published its thinking on AI agent memory. It's a great article about storage. It's also proof that the industry is still missing the point.
Last month, Databricks published a blog post titled "Memory Scaling for AI Agents." It's worth reading. It's also worth pushing back on.
The article makes three arguments that are all correct:
First, AI agents need persistent memory to be useful beyond single-session interactions. Second, this memory should distinguish between episodic (raw interaction logs) and semantic (distilled patterns) representations. Third, raw memory accumulation doesn't scale — you need periodic distillation to keep storage tractable and consolidation pipelines to remove duplicates, prune outdated information, and resolve conflicts.
Every one of these points is true. And yet the article reveals something important about how the industry is approaching this problem.
Databricks is solving a storage problem. But agent memory isn't a storage problem. It's a cognition problem.
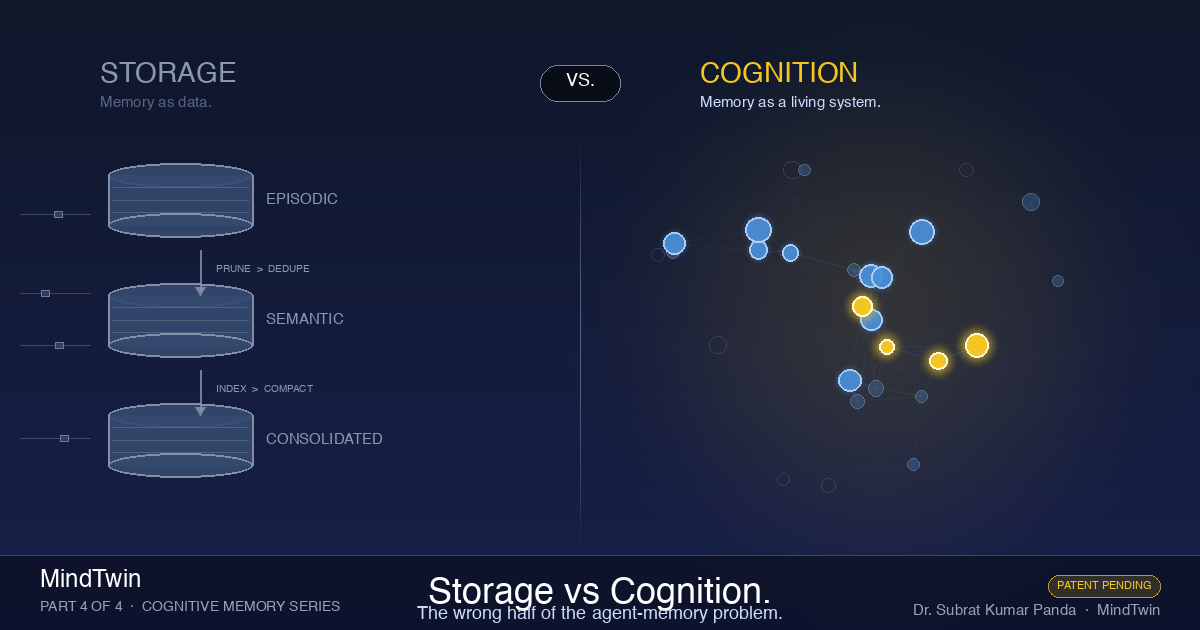
The Two Paradigms
There are two ways to think about memory in AI systems.
The first paradigm treats memory as data. You have inputs (interactions, documents, events). You store them. You index them. When you need them, you retrieve them. When they get stale, you prune them. When there are conflicts, you resolve them with pipelines. This is the paradigm Databricks is operating in, and it's the paradigm almost every enterprise data team understands natively. It's the lakehouse mental model applied to AI state.
The second paradigm treats memory as cognition. Memory isn't stored — it's alive. It decays naturally when not reinforced. It strengthens when accessed. It consolidates over time from specific events into abstract wisdom. It flags certain experiences as defining moments and protects them forever. It emerges, rather than being engineered.
These aren't two different implementations of the same idea. They're two fundamentally different philosophies about what memory is.
The storage paradigm asks: how do we manage this data efficiently at scale?
The cognition paradigm asks: how do we make this system develop an understanding of itself and its context over time?
What the Databricks Article Shows
Read the Databricks piece carefully and you'll notice what's present — and what isn't.
What's present: Ingestion of enterprise documents. Storage tiers for episodic and semantic memory. Retrieval mechanisms. Distillation pipelines. Deduplication logic. Conflict resolution.
What's absent: Any mention of decay, forgetting curves, salience, flashbulb memories, activation, reinforcement, or any of the fifty years of cognitive architecture research that has modeled how real memory systems actually work.
This absence isn't an oversight. It's a worldview.
When a data engineering company looks at the problem of agent memory, they see what they have tools for: storage, indexing, pipelines, ETL. These tools are excellent, and they produce a functional system. You can build an agent on top of Databricks's memory architecture and it will work.
But it won't be intelligent about what it knows. It will be efficient about what it stores. Those are different things.
The Three Things Storage Can't Do
There are three capabilities that no amount of storage engineering can produce. They emerge only from a cognitive architecture.
1. Knowing what to forget without being told.
Databricks addresses stale data through "pipelines that prune outdated information." But pruning requires someone to know what's outdated. That someone is either a human curator (doesn't scale) or a rule-based system (catches the obvious cases and misses everything subtle).
Mathematical decay solves this without any curation. Information that isn't referenced naturally loses activation. Over time, it falls below the retrieval threshold. It isn't deleted — it just stops being surfaced. If it becomes relevant again, a single access can rebuild its activation. This is how your brain handles the thousands of things you've learned and don't currently need. No prune scripts. No cleanup sprints. Just physics.
2. Knowing what matters without being asked.
Nothing in the Databricks architecture identifies which memories are more important than others. Every episodic memory is treated as equal input to the distillation process. This means the signal-to-noise ratio of what emerges is entirely dependent on the signal-to-noise ratio of what went in.
A salience detection mechanism changes this. When the system can automatically score incoming interactions for emotional intensity, explicit intent, and novelty relative to existing patterns — and then surface the high-scoring ones for human validation — the memory system becomes actively curated without requiring human curation effort. The mathematics does the work of noticing. The human does the work of confirming. Neither has to do both.
3. Protecting what's irreplaceable.
In a pipeline-based memory system, every episodic memory eventually becomes input to distillation. Maybe it's preserved in the compressed semantic layer, maybe it isn't. You don't get to decide that your wedding day, your first customer, or your team's watershed architectural decision must survive forever in full detail.
A cognitive architecture handles this differently. When a human validates that a specific memory represents a defining moment, that memory's decay rate drops to effectively zero and its importance weight spikes. The consolidation process is explicitly instructed to exclude it. The memory dominates retrieval permanently. It isn't just stored — it's protected.
Storage systems treat all data as potentially disposable. Cognitive systems recognize that some data is identity.
Why This Matters More Than It Seems
You could read the above and conclude that the difference is academic. Databricks builds for enterprises that need functional agent memory at scale. If the agent works, who cares whether the memory architecture is "biologically coherent"?
The answer: you'll care the moment the agent starts being wrong about things.
Every memory system eventually hits the same failure mode. It confidently surfaces outdated information. It misses the significance of a pivotal conversation. It treats a casual comment and a strategic commitment with equal weight. It forgets what matters and remembers what doesn't.
When this happens in a storage-based system, the fix is a new pipeline. A better deduplication strategy. A more aggressive pruning schedule. More metadata, more tags, more rules. Each fix adds complexity. The system gets harder to maintain, not easier. And the fundamental problem — that the architecture wasn't designed to know what matters — never goes away.
When this happens in a cognitive system, the fix is built into the model. Unused information has already faded. Salient information has already been flagged. Protected information has already been preserved. The system's behavior isn't a function of how many rules you've added — it's a function of the mathematics at the core of the design.
This isn't a minor optimization. It's the difference between a system that degrades over time and a system that improves over time.
The Market Signal
Here's what Databricks publishing this article really means: the industry has acknowledged that agent memory is the next battleground for enterprise AI. When the largest data platform in the world starts writing thought-leadership pieces about a problem, that problem is about to get a lot of attention.
This is good for everyone working in this space. It means enterprise buyers will start asking the right questions. It means technical executives will understand the stakes. It means investors will look harder at companies working on memory architecture.
But it also means the paradigm gap is going to matter sooner than later. As the market educates itself about what agent memory should do, sophisticated buyers will start asking the questions that Databricks's approach can't answer:
How does your system know what to forget?
How does it identify what matters?
How does it protect the memories that define who we are?
The answer "we have distillation pipelines" works until someone has lived with a storage-based memory system long enough to see where it breaks. Then the answer stops working.
The Path Forward
The Databricks article does something valuable: it puts agent memory on the map for enterprise data leaders who hadn't been thinking about it. That's genuinely useful.
But mapping the problem is different from solving it. And the solution the article describes — bootstrap, distill, consolidate — is what you do when you're treating memory as a scaling challenge for data storage.
The solution when you're treating memory as a cognitive challenge looks different. It uses mathematical decay instead of pruning pipelines. It uses salience detection instead of uniform ingestion. It uses human validation of defining moments instead of blanket distillation. It models the memory system the way the brain does — because fifty years of cognitive science has already figured out what works.
The storage paradigm will keep improving. Databricks will ship better distillation tools. Other platforms will ship better indexing. This is fine. This is useful.
But the systems that will actually make AI agents feel like they know you, feel like they remember, feel like they've been with you on the journey — those won't be built on top of the storage paradigm. They'll be built on a different philosophy entirely.
Memory as cognition. Not memory as data.
That's the gap. And that's where we're working.
The Cognitive Memory Series
- Part 1: Your AI Has Amnesia
- Part 2: Forbes and Organizational Memory
- Part 3: The $20 Trillion Memory Problem
- → Part 4: Storage vs Cognition (you are here)
- Part 5: The Fourth Dimension